
Learning to Design Accurate Deep Learning Accelerators with Inaccurate Multipliers

Design, Automation and Test in Europe Conference and Exhibition, 2022
DOI: 1558-1101
Abstract
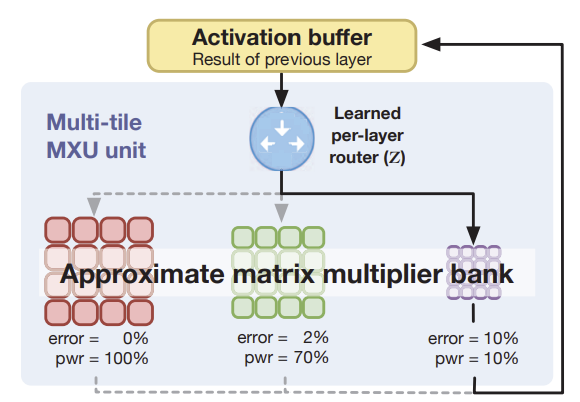
Approximate computing is a promising way to improve the power efficiency of deep learning. While recent work proposes new arithmetic circuits (adders and multipliers) that consume substantially less power at the cost of computation errors, these approximate circuits decrease the end-to-end accuracy of common models. We present AutoApprox, a framework to automatically generate approximate low-power deep learning accelerators without any accuracy loss. AutoApprox generates a wide range of approximate ASIC accelerators with a TPUv3 systolic-array template. AutoApprox uses a learned router to assign each DNN layer to an approximate systolic array from a bank of arrays with varying approximation levels. By tailoring this routing for a specific neural network architecture, we discover circuit designs without the accuracy penalty from prior methods. Moreover, AutoApprox optimizes for the end-to-end performance, power and area of the the whole chip and PE mapping rather than simply measuring the performance of the arithmetic units in iso-lation. To our knowledge, our work is the first to demonstrate the effectiveness of custom-tailored approximate circuits in delivering significant chip-level energy savings with zero accuracy loss on a large-scale dataset such as ImageNet. AutoApprox synthesizes a novel approximate accelerator based on the TPU that reduces end-to-end power consumption by 3.2% and area by 5.2% at a sub-10nm process with no degradation in ImageNet validation top-1 and top-5 accuracy.