
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai
Saurav Kadavath
Sandipan Kundu
Amanda Askell
Jackson Kernion
Andy Jones
Anna Chen
Anna Goldie

Cameron McKinnon
Carol Chen
Catherine Olsson
Christopher Olah
Danny Hernandez
Dawn Drain
Deep Ganguli
Dustin Li
Eli Tran-Johnson
Ethan Perez
Jamie Kerr
Jared Mueller
Jeffrey Ladish
Joshua Landau
Kamal Ndousse
Kamile Lukosuite
Liane Lovitt
Michael Sellitto
Nelson Elhage
Nicholas Schiefer
Noemi Mercado
Nova DasSarma
Robert Lasenby
Robin Larson
Sam Ringer
Scott Johnston
Shauna Kravec
Sheer El Showk
Stanislav Fort
Tamera Lanham
Timothy Telleen-Lawton
Tom Conerly
Tom Henighan
Tristan Hume
Samuel R. Bowman
Zac Hatfield-Dodds
Ben Mann
Dario Amodei
Nicholas Joseph
Sam McCandlish
Tom Brown
Jared Kaplan
Anthropic, 2022
DOI: 2212.08073v1
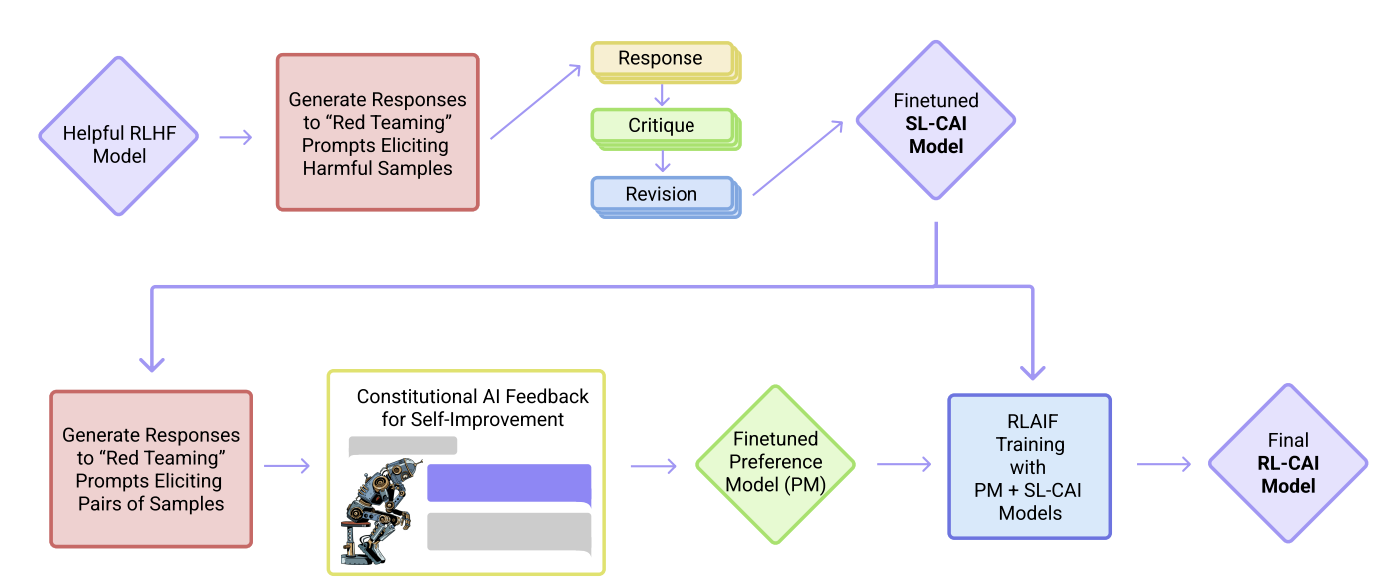
Abstract
As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through selfimprovement, without any human labels identifying harmful outputs. The only human oversight is provided through a list of rules or principles, and so we refer to the method as ‘Constitutional AI’. The process involves both a supervised learning and a reinforcement learning phase. In the supervised phase we sample from an initial model, then generate self-critiques and revisions, and then finetune the original model on revised responses. In the RL phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better, and then train a preference model from this dataset of AI preferences. We then train with RL using the preference model as the reward signal, i.e. we use ‘RL from AI Feedback’ (RLAIF). As a result we are able to train a harmless but nonevasive AI assistant that engages with harmful queries by explaining its objections to them. Both the SL and RL methods can leverage chain-of-thought style reasoning to improve the human-judged performance and transparency of AI decision making. These methods make it possible to control AI behavior more precisely and with far fewer human labels.