
TRACE: Capability-Targeted Agentic Training




TL;DR
LLM agents fail in complex environments because they lack specific capabilities — but when training with RL directly on the target environment, the reward signal doesn’t reveal which underlying capabilities the agent lacks. TRACE (Turning Recurrent Agent failures into Capability-targeted training Environments) is an end-to-end system for environment-specific agent self-improvement that automatically identifies an agent’s capability deficits, synthesizes targeted training environments for each, and trains lightweight LoRA adapters via RL. TRACE improves over the base agent by +14.1 points on τ2-Bench and +7 perfect scores on ToolSandBox, outperforming the strongest baseline by +7.4 points and +4 perfect scores.
Table of Contents
Overview
LLM agents in environments like customer service or tool use must exercise multiple capabilities across different tasks. A natural approach is to train the agent directly on the target environment via RL — but the reward signal doesn’t reveal which underlying capabilities the agent lacks, making learning sparse and sample-inefficient. TRACE decomposes the problem into four steps:
- Capability Selection. Roll out the base agent, then contrast successful and failed trajectories to identify the specific capabilities the agent lacks.
- Synthetic Environment Generation. For each identified capability deficit, synthesize a targeted training environment that isolates and rewards exercising that capability.
- GRPO Training. Train a lightweight LoRA adapter on each capability-specific synthetic environment via RL.
- Select & Adapt. At inference, route each task to the relevant LoRA adapter using the base model as a classifier.
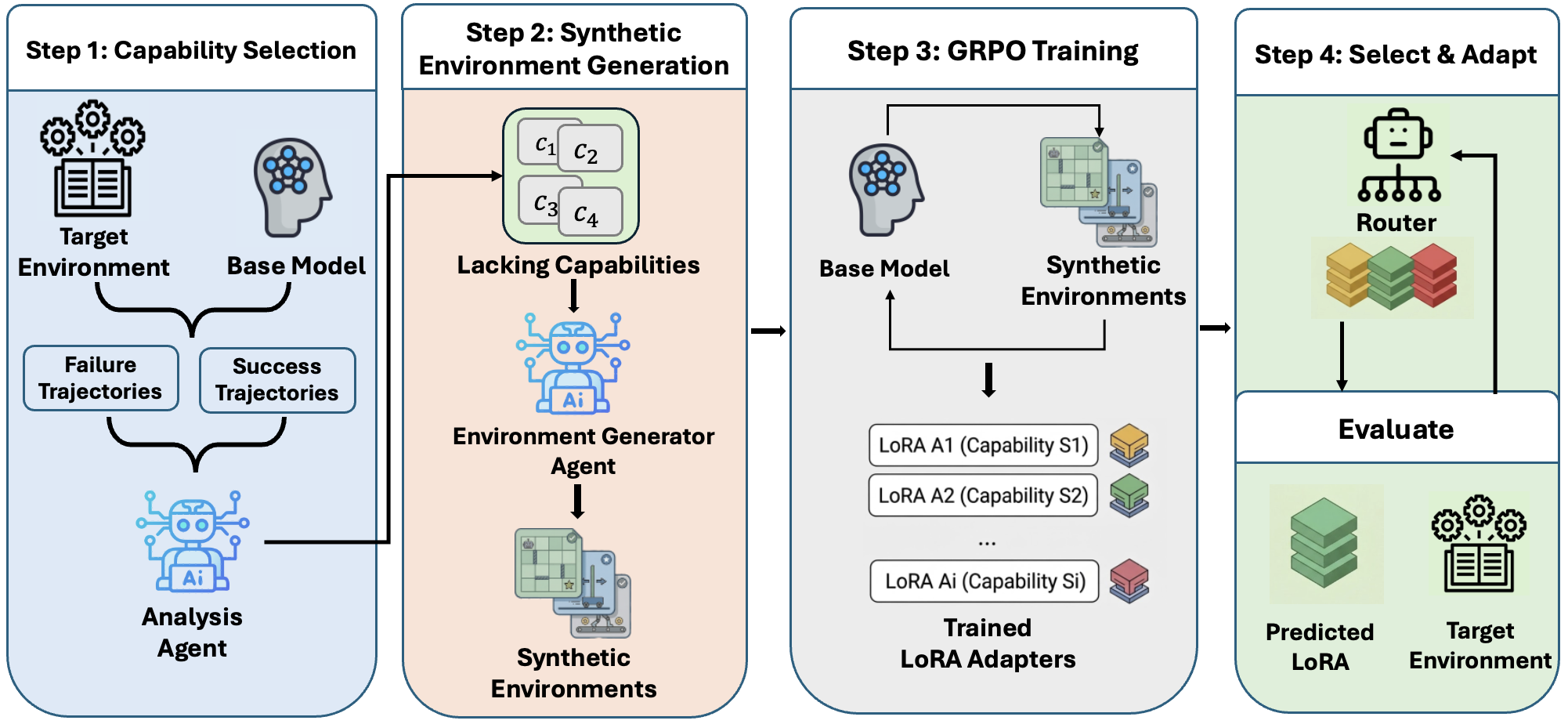
Overview of TRACE. An analysis agent identifies capability deficits from the agent's trajectories. For each deficit, a generation agent synthesizes a targeted training environment. A LoRA adapter is trained via GRPO on each environment, and a router selects the appropriate adapter at inference.
Main Results
We evaluate TRACE using Qwen3-30B-A3B on two benchmarks: τ2-Bench (customer service with Airline and Retail domains) and ToolSandBox (stateful tool use, 129 scenarios).
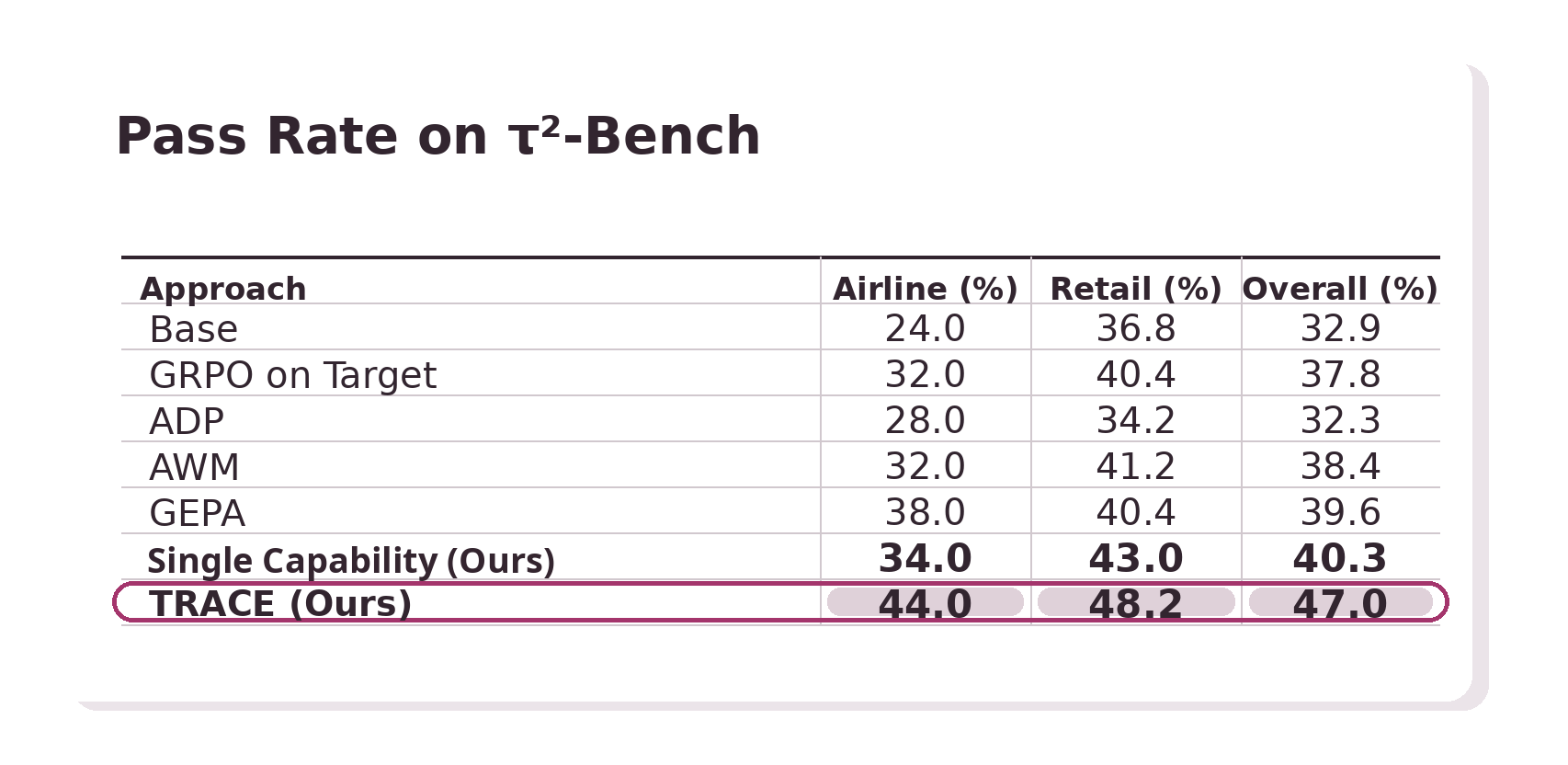
τ2-Bench: Pass Rate
ToolSandBox: Perfect Score & Mean Similarity
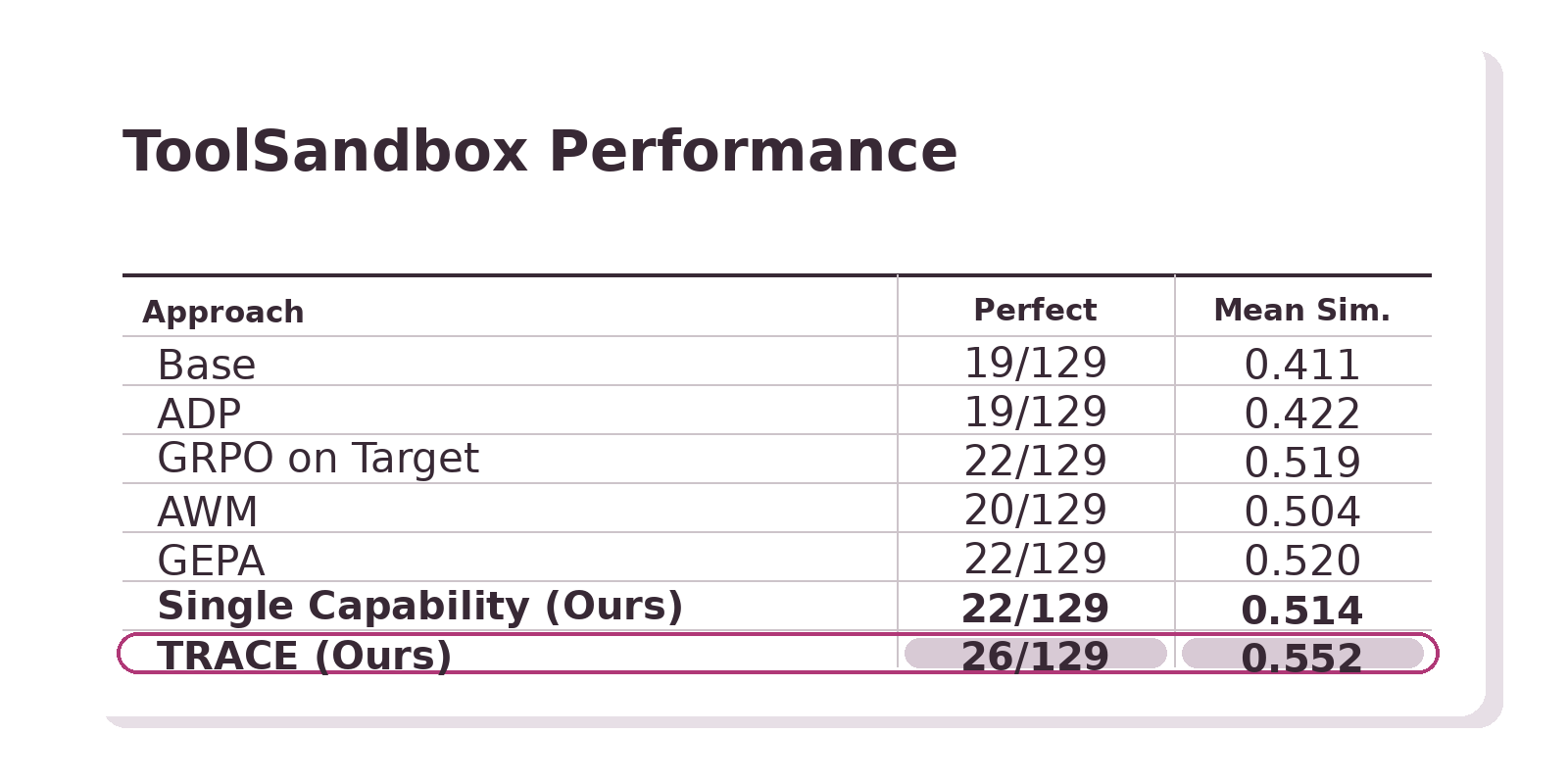
On τ2-Bench, even a single adapter trained on one synthesized capability environment surpasses direct GRPO on the target environment, GEPA (evolutionary prompt optimization), and methods that curate general-purpose synthetic agentic data and environments (ADP and AWM). Combining multiple capability-specific adapters with routing, TRACE achieves the strongest results on both benchmarks.
Scaling Behavior
Scaling with Number of Rollouts
TRACE scales more efficiently with training rollouts than both GRPO (direct RL on the target environment) and GEPA (evolutionary prompt optimization). On τ2-Bench, TRACE shows consistent, monotonic improvement up to 47.0% at 5,120 rollouts, while GRPO stalls at 37.8% and GEPA plateaus at 39.6%. A consistent trend appears on ToolSandBox.
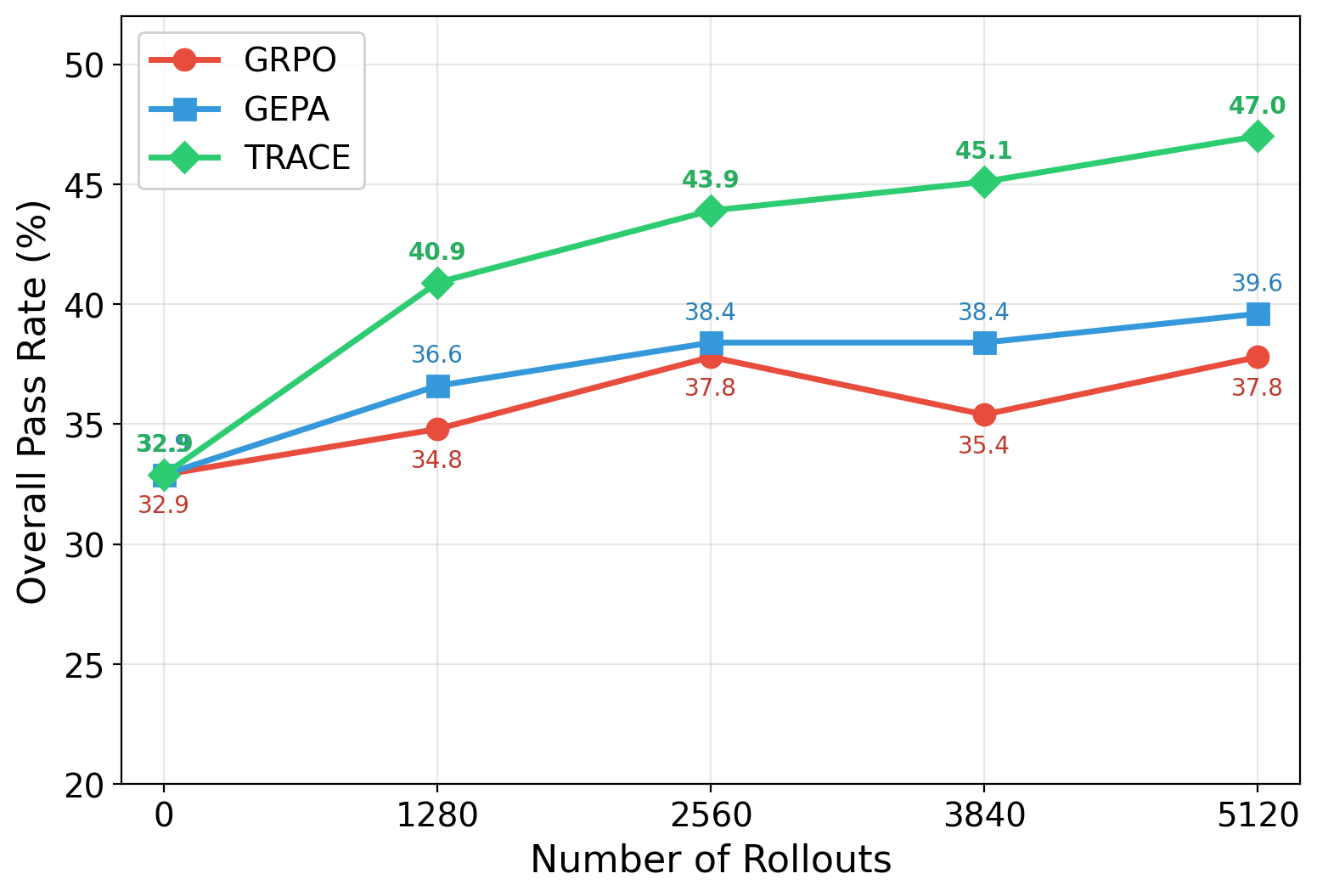
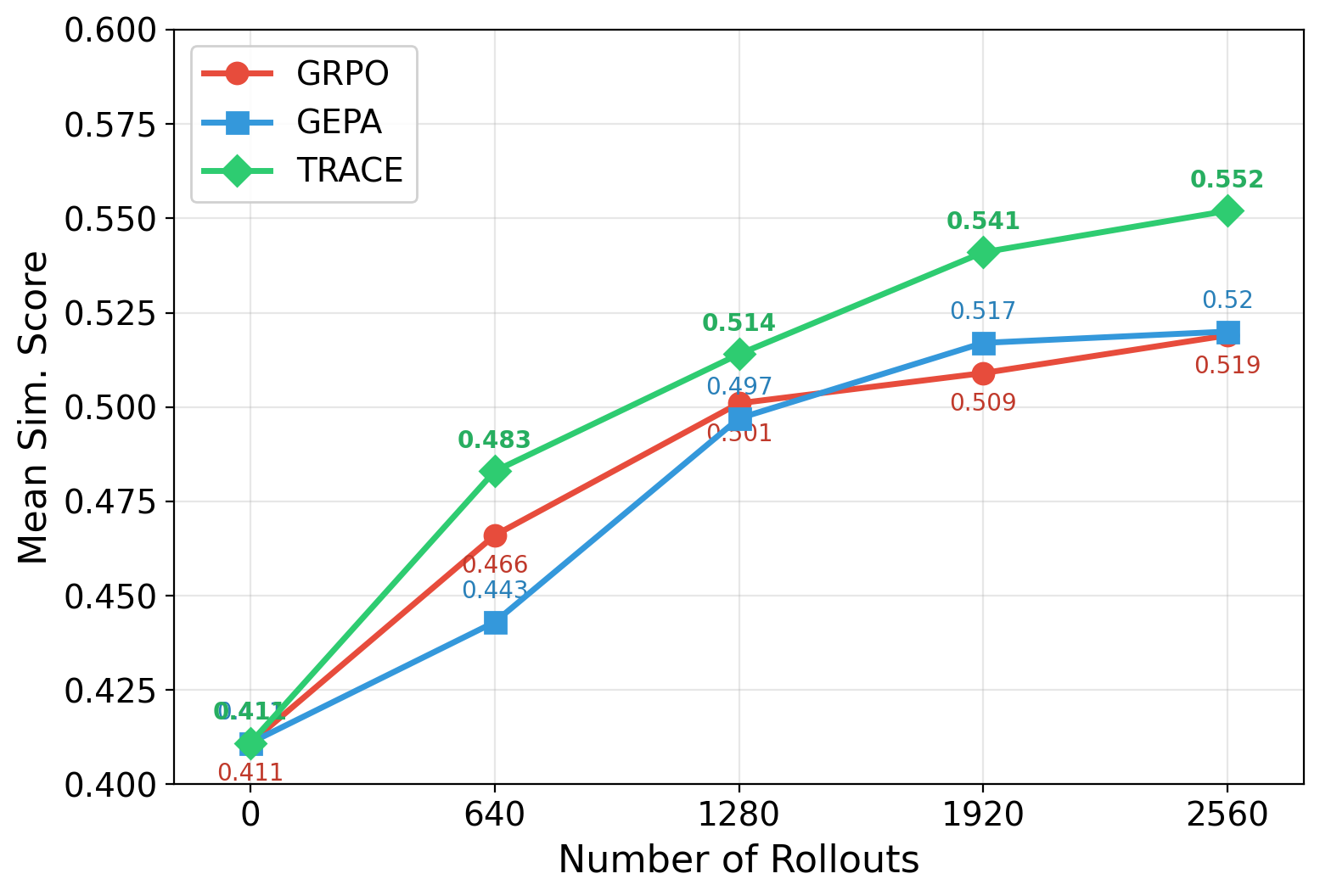
Performance scaling with number of rollouts on τ2-Bench (left) and ToolSandBox (right). TRACE scales consistently while baselines plateau.
Scaling with Number of Capabilities
TRACE continues to improve as more capability-specific adapters are added, reaching 47.0% with 4 capabilities. In contrast, GEPA’s prompt-based approach plateaus quickly — demonstrating that explicitly training on capability-targeted environments enables more significant gains.
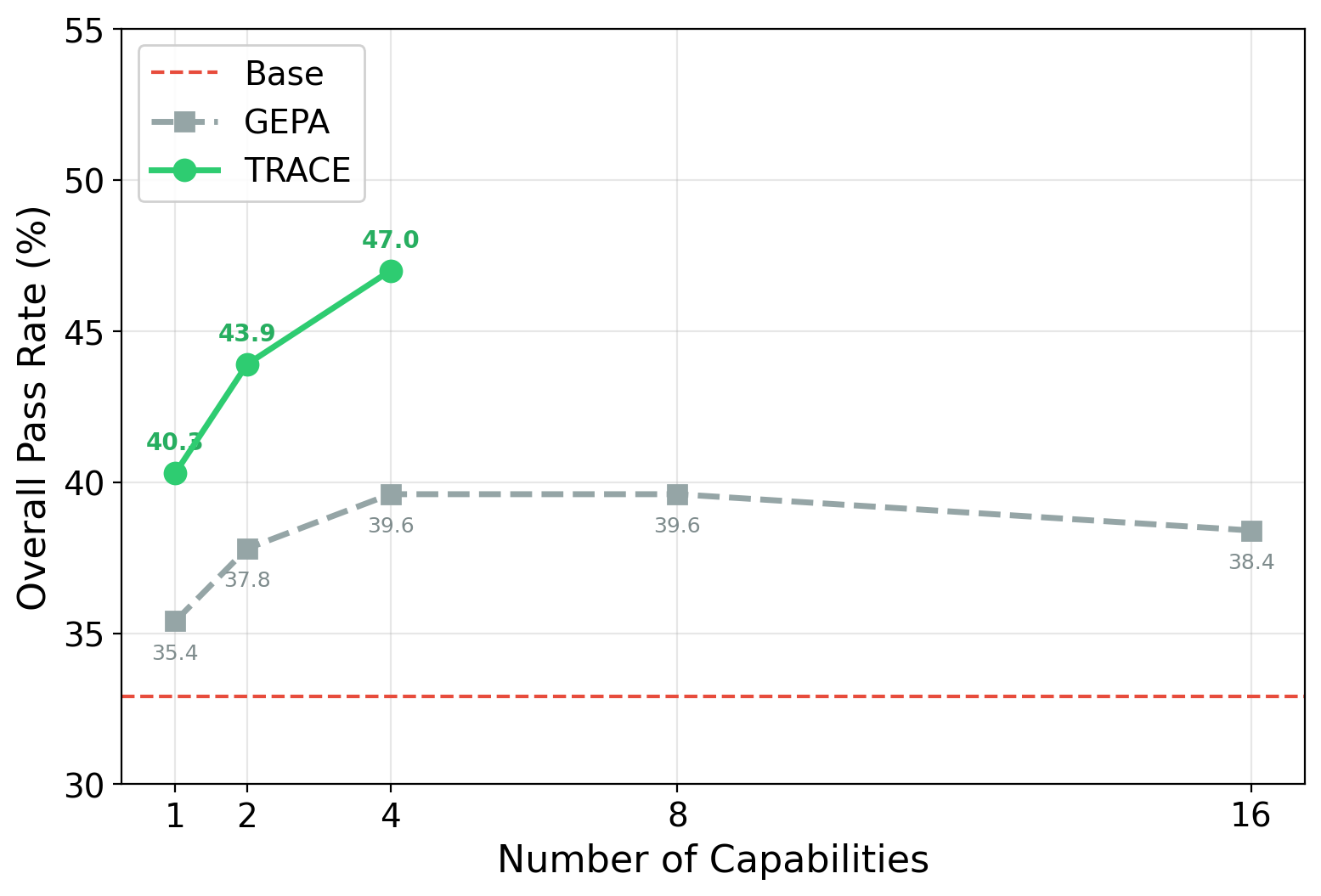
Overall pass rate on τ2-Bench as the number of capabilities increases. TRACE with trained LoRA adapters scales steadily, while GEPA's prompt-based approach saturates.
Acknowledgements
We thank the Scaling Intelligence Lab and others for their constructive feedback, especially Debangshu Banerjee, Tanvir Bhathal, Alex Bloom, Andy Dimnaku, Simon Guo, Sid Jha, Hermann Kumbong, Jacky Kwok, Andrew Shi, and Shayan Talaei. We also thank Prime Intellect, Lambda Labs, Google, and IBM for providing compute resources.
Citation
If you find TRACE useful, please use the following citation:
@misc{kang2026tracecapabilitytargetedagentictraining,
title={TRACE: Capability-Targeted Agentic Training},
author={Hangoo Kang and Tarun Suresh and Jon Saad-Falcon and Azalia Mirhoseini},
year={2026},
eprint={2604.05336},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2604.05336},
}