



TL;DR: OpenJarvis is an open-source framework for personal AI agents that runs entirely on-device. It provides shared primitives for building on-device agents, efficiency-aware evaluations, and a learning loop that improves models using local trace data.
🚨 Download OpenJarvis today and top the ENERGY leaderboard for a chance to win a Mac Mini! 🚨
In the 1970s and 80s, computing moved from mainframes to personal computers. Not because PCs were more powerful, but because they became efficient enough for what people actually needed. AI is reaching a similar moment.
In our recent Intelligence Per Watt study, we found that local language models and local accelerators can accurately service 88.7% of single-turn chat and reasoning queries at interactive latencies, with intelligence efficiency improving 5.3× from 2023 to 2025.
At the same time, personal AI is exploding. Frameworks like OpenClaw have attracted more than 250,000 GitHub stars, inspiring a wave of agents (PicoClaw, NanoBot, IronClaw, TinyClaw, MimicLaw, ZeroClaw, etc) all built around the same idea: AI that operates over your personal context, interacting through the platforms you already use.
Put these together and the architecture seems obvious: personal AI should run on your personal device.
In nearly all of today's personal AI projects, the local component is a thin orchestration layer, while the "brain" lives in someone else's data center. Your most personal data routes through cloud APIs, with their latency, their cost, and their terms of service.
We built OpenJarvis to fix this.
OpenJarvis is an opinionated framework for personal AI running on your personal devices. It provides shared primitives for building on-device agents, evaluations that treat metrics such as energy, FLOPs, latency, and dollar cost as first-class constraints, and a learning loop that improves models using local trace data.
The goal is simple: make it possible to build personal AI agents that run locally by default, calling the cloud only when truly necessary. OpenJarvis aims to be both a research platform and production foundation for local AI, in the spirit of PyTorch.
🏢 OpenJarvis: The Local-First Personal AI Stack
OpenJarvis emerged from a simple question: what's standing in the way of personal AI running locally today? We believe the answer comes down to three missing pieces in today's local AI systems:
- Shared abstractions. Teams assemble bespoke stacks, choosing independently among model servers, orchestration frameworks, memory stores, tool interfaces, and adaptation pipelines. The result is duplicated effort and brittle, non-interoperable systems. There is no agreed-upon "local AI software stack" the way there is for web development or mobile apps.
- Efficiency-aware evaluations: Systems are tuned for task quality alone, even though on-device deployments must jointly satisfy constraints on latency, energy, memory footprint, and dollar cost. Efficiency isn't a nice-to-have on a laptop running on battery; it's a hard requirement.
- Closed-loop optimization Because most AI systems run in the cloud, the pieces needed for local improvement don't exist: trace data isn't available, model weights are closed, and the runtime isn't tunable. This makes it nearly impossible to study or build personal AI agents that improve over time.
To close these gaps, we built OpenJarvis. OpenJarvis is the open-source stack for personal AI agents that runs entirely on-device. Designed to serve as both a research platform and deployment-ready infrastructure, OpenJarvis does three things:
- Defines a set of composable primitives that replace ad hoc integration with an opinionated framework of five primitives — Intelligence, Engine, Agents, Tools & Memory, and Learning — providing the shared abstractions the ecosystem currently lacks. These primitives can be studied individually or as an integrated whole.
- Makes efficiency a first-class evaluation target by tracking energy, dollar cost, FLOPs, latency, and related system metrics alongside accuracy. These measurements are essential for optimizing edge deployments, where resource constraints are fundamental.
- Provides an optimization harness for deploying optimization strategies across the complete local AI stack: 1) model weights, 2) LM prompts, 3) agentic logic, and 4) inference engine. By learning from local trace data, the harness applies the best optimization strategies to-date while giving researchers a testbed to explore new approaches tailored to the trace signatures that distinguish personal AI (i.e., long-horizon sessions, persistent cross-session context, non-stationary user preferences).
🧱 Primitives for On-Device AI
OpenJarvis is structured around five composable primitives. Each primitive can be benchmarked, substituted, and optimized independently, or analyzed within the context of the full system. Collectively, these primitives define modular, hardware-aware abstractions that support both standalone use and system-level composition.

Figure 1: The five primitives of OpenJarvis (Intelligence, Engine, Agents, Tools & Memory, and Learning) form a composable, hardware-aware stack for on-device personal AI.
🧠 Intelligence: On-Device Language Models
The Intelligence primitive is the model layer: the on-device language models that provide reasoning, generation, and understanding. Recent progress in open models has made personal AI on consumer hardware newly practical. Families like Qwen, GPT-OSS, Gemma, Granite, GLM, Kimi, and others now span a wide range of sizes, context lengths, and efficiency profiles, making it possible to match meaningful capability to local hardware.
OpenJarvis sits above that rapidly changing landscape with a unified model catalog. Rather than forcing users to track model releases, parameter counts, or memory tradeoffs, OpenJarvis lets them specify the capability they need and then determines what their hardware can realistically support. The goal is not just model access, but a stable interface over a fast-moving ecosystem — one that makes it possible to study how model choice, independent of agent logic or inference backend, affects task quality, efficiency, and personalization over time.
⚙️ Engine: Hardware-Aware Inference
The Engine primitive is the execution layer: the inference backend that determines how models actually run on a device. Local inference today is powerful but fragmented, with backends such as Ollama, vLLM, SGLang, llama.cpp, Apple Foundation Models, Exo, Nexa, and Mirai Uzu each offering different strengths depending on platform, memory, and performance constraints.
OpenJarvis provides a hardware-aware interface over that fragmentation. With commands like jarvis init, it detects the user's system and recommends an engine and model configuration suited to the available hardware; with jarvis doctor, it helps keep that setup healthy over time.
🤖 Agents: Composable Reasoning
The Agents primitive is the behavior layer: the reasoning patterns that turn raw model capability into structured action. Existing approaches such as ReAct (Yao et al., 2023) and OpenHands (Wang et al., 2024) show how models can plan, call tools, and iterate on tasks, but many agent frameworks assume abundant compute and memory. On-device systems require something more disciplined: agents that can reason effectively within bounded context windows, limited working memory, and strict efficiency constraints.
OpenJarvis provides a composable set of agent roles designed for those constraints. It supports established reasoning patterns while introducing roles such as the Orchestrator, which breaks complex tasks into subtasks and delegates them, and the Operative, a lightweight executor for recurring personal AI workflows. Rather than relying on a single general-purpose agent, OpenJarvis lets developers combine specialized agents for planning, delegation, and execution on local hardware.
🔧 Tools & Memory: Grounding Intelligence in the Real World
The Tools & Memory primitive is the grounding layer: the mechanisms that connect intelligence to the outside world and to persistent personal context. Models become far more useful when they can retrieve documents, call tools, communicate with other agents, and operate across the channels where users already live. The challenge is that these integrations are often inconsistent, cloud-dependent, or difficult to compose.
OpenJarvis provides a local-first interaction pattern over both tools and memory. It includes native support for MCP (Model Context Protocol) for standardized tool use, Google A2A (Agent-to-Agent) for inter-agent communication, and semantic indexing for local retrieval over papers, notes, and documents. It also connects to a broad set of messaging platforms, webchat, and webhooks. The result is a system whose intelligence is grounded in the user's actual environment, while keeping storage and control local by default.
📚 Learning: Self-Improving Systems
The Learning primitive is the adaptation layer: the mechanisms that help the system get better over time. Techniques such as supervised fine-tuning, LoRA, GRPO, and bandit-based routing have made model and agent improvement more accessible, but in most systems these remain separate from everyday use. Personal AI should not just run locally; it should learn locally from accumulated interaction and feedback.
OpenJarvis turns that idea into an operational loop. Its learning layer uses personal traces to synthesize training data, refine agent behavior, and improve model selection over time, with commands like jarvis optimize packaging that process into a usable workflow.
⚡ Efficiency as a First-Class Metric
Most AI frameworks treat efficiency as an afterthought. OpenJarvis inverts this: energy and dollar cost are first-class design constraints alongside accuracy from the start.
OpenJarvis includes a hardware-agnostic telemetry system that profiles energy consumption across NVIDIA GPUs (via NVML), AMD GPUs, and Apple Silicon (via powermetrics), sampling at 50ms intervals. The jarvis bench command provides standardized benchmarking of latency, throughput, and energy per query. A built-in dashboard visualizes cost savings, model comparisons, and efficiency metrics in real time.
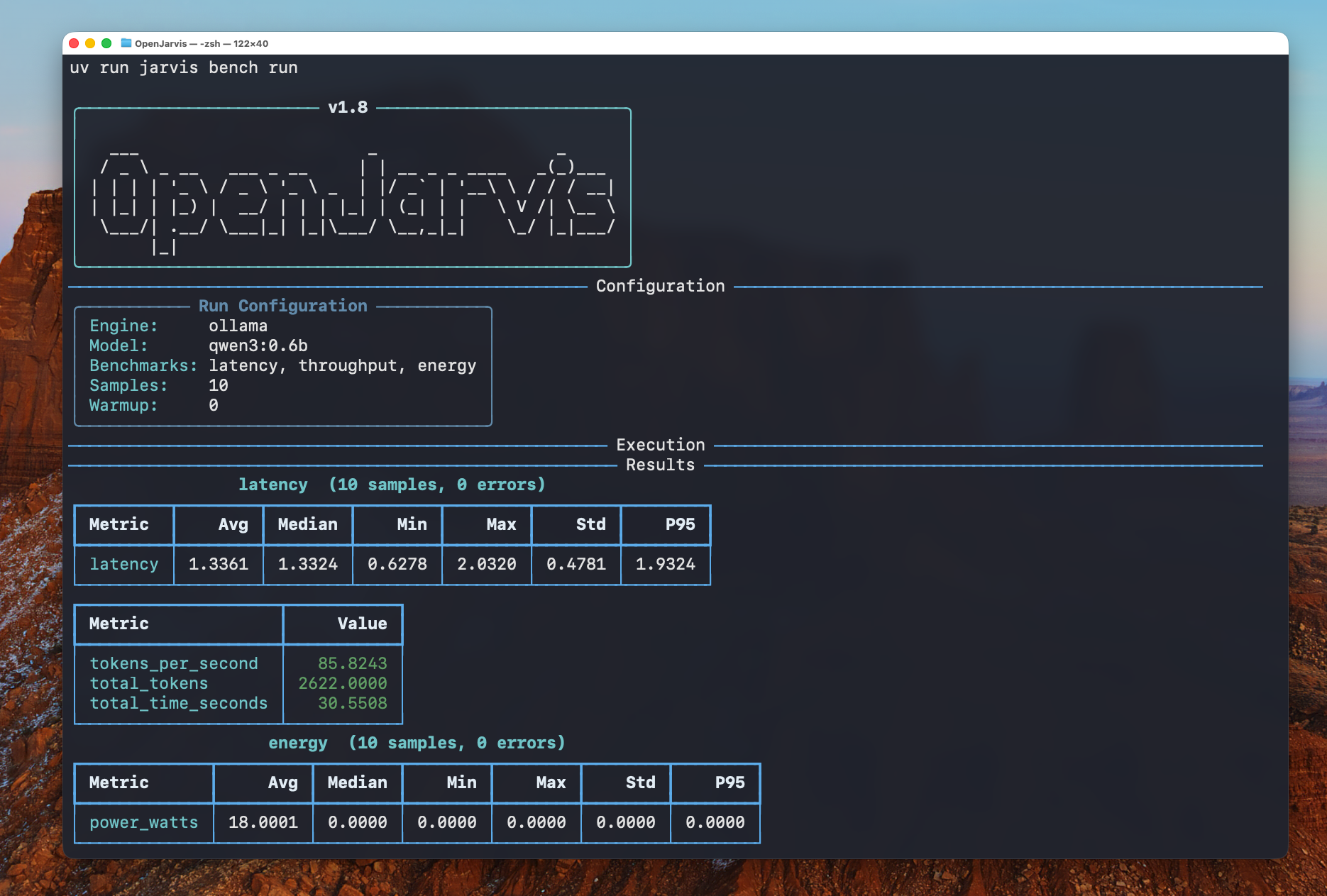
Figure 2: The OpenJarvis dashboard provides real-time visibility into inference latency, energy consumption, cost savings, and model performance across local and cloud configurations.
🔒 Learning from Local Traces
Because execution is local and interaction traces remain on-device, OpenJarvis captures rich, structured trace data across every layer of the stack — from raw inference telemetry and prompt–completion pairs to agent decision trajectories and tool call sequences. This local trace infrastructure enables closed-loop optimization across four layers of the stack:
- Model weights — gradient-based updates including SFT, GRPO, DPO, and other reinforcement learning from human feedback methods that fine-tune local model parameters directly.
- LM prompts — prompt optimization strategies such as DSPy that automatically refine instructions and few-shot examples to improve task performance without modifying model weights.
- Agentic logic — agent-level optimization approaches like GEPA that improve how agents decompose tasks, select tools, and coordinate sub-agents.
- Inference engine — engine-level tuning including quantization selection, batch scheduling, and hardware-specific kernel configuration.
🚀 What Can You Do With OpenJarvis?
OpenJarvis can be used from the command line (jarvis ask, jarvis chat), through a browser-based dashboard with built-in webchat, or via a Tauri-based desktop app on macOS, Linux, and Windows.

Figure 3: OpenJarvis supports interaction via CLI, browser dashboard, desktop app, and 26+ messaging channels.
Here are some ways to use it!
- Personal AI tasks. Email triage, morning briefings, daily digests, and scheduled summaries that run on a cron schedule without cloud dependencies. Point OpenJarvis at a folder of papers or notes and it builds a local knowledge base for question answering and research. Connect it to your messaging platforms and interact through iMessage, Telegram, WhatsApp, or whatever you already use. Critically, all of your personal details, documents, messages, and preferences stay on your device, unlike cloud-based systems that send everything to external servers.
- Traditional LM workloads. Open-ended chat, mathematical and scientific reasoning, code generation, knowledge-intensive question answering, and structured output generation, all running locally with energy and cost tracked per query.
- Agentic and long-horizon tasks. The scheduler enables cron-based automation ("every morning at 7am, pull my calendar, check my email, and prepare a briefing") while the agent framework supports multi-step workflows like code review, web research, and document processing pipelines.
🤝 Get Involved
OpenJarvis is a first step toward establishing a core framework for personal AI on personal devices. As local models and consumer hardware become more performant, we need better infrastructure for running AI agents on-device, reducing reliance on cloud APIs while keeping your most personal data exactly where it belongs. OpenJarvis is open-source under Apache 2.0 because the tools for studying and building local-first AI should be available to everyone, and because these problems are too large for any single lab to solve alone.
If you are a researcher, developer, or user, we would love to get you involved.
- Researchers: We see major opportunities for further research, including advances in local language models, efficient agent architectures, memory management for on-device systems, and learning approaches that improve with use while preserving privacy. OpenJarvis provides an evaluation harness spanning 30+ benchmarks, and we would love for you to use it to measure and push progress.
- Developers: We encourage you to build on top of OpenJarvis and help us understand where the real bottlenecks are. Which use cases matter most? Where does performance fall short? Please visit our GitHub to get started. We welcome PRs that expand the ecosystem.
- Users: Try it out and tell us what you think. Point it at your files, connect it to your messaging platforms, and let us know what works and what does not. The fastest way to get started is to run
pip install openjarvis, thenjarvis init. Join us on discord and share your thoughts!
The fastest way to get started:
# Install
git clone https://github.com/open-jarvis/OpenJarvis.git
cd OpenJarvis
uv sync # core framework
uv sync --extra server # + FastAPI server
# Let it Rip!
jarvis init # auto-detect hardware, recommend engine
jarvis doctor # verify setup
jarvis ask "What is the capital of France?"
🙏 Acknowledgements
We are grateful to Ollama, IBM Research, Laude Institute, Stanford Marlowe, Stanford HAI, Google Cloud Platform, Lambda Labs, Stanford NLP, and Stanford AI Lab for their generous support.
OpenJarvis is part of Intelligence Per Watt, a research initiative studying the efficiency of on-device AI systems. The project is developed at Hazy Research and the Scaling Intelligence Lab at Stanford SAIL.
Full Author List
Jon Saad-Falcon*, Avanika Narayan*, Herumb Shandilya, Hakki Orhun Akengin, Robby Manihani, Gabriel Bo, John Hennessy, Christopher Ré, Azalia Mirhoseini
Citation
@misc{saadfalcon2026openjarvis,
title={OpenJarvis: Personal AI, On Personal Devices},
author={Jon Saad-Falcon and Avanika Narayan and Herumb Shandilya and Hakki Orhun Akengin and Robby Manihani and Gabriel Bo and John Hennessy and Christopher R\'{e} and Azalia Mirhoseini},
year={2026},
howpublished={\url{https://scalingintelligence.stanford.edu/blogs/openjarvis/}}
}