
Toward Better HIP Kernel Generation for AMD GPUs: Synthetic Data, Multi-Agent Search, and Reinforcement Learning







TLDR
In this work, we explore how to make language models better at generating high performance HIP kernels for AMD GPUs. We present the following:
-
A synthetic dataset of 500 new PyTorch reference tasks using mutation, composition, and constraint-based generation to cover a broader range of workloads.
-
A multi-agent optimization pipeline for HIP kernel generation. Instead of relying on single-shot prompting, we used specialized agents for task generation, PyTorch-to-HIP translation, hardware evaluation, and evolutionary optimization to search for faster kernels.
-
A framework based on small, low-cost open source models using SFT followed by GRPO RL. While SFT helped the model learn correct HIP patterns, RL pushed performance further by directly rewarding correctness and speedup on MI350X GPUs.
Our results showed improvements in both compilation and correctness rates across all KernelBench levels, with RL providing the strong gains. However, achieving meaningful speedup over PyTorch still requires much deeper hardware awareness and optimization reasoning. From here, we look to integrate the ROCm profiler to teach the model hardware profiler-based rewards.
Motivation
The performance of every modern AI workload is bottlenecked by kernel quality. Writing high-performance kernels requires deep familiarity with hardware, low-level languages, and optimization techniques that are critically scarce outside NVIDIA’s CUDA ecosystem.
AMD’s HIP is a good example of this deficit. It’s a compiler-verified, low-level programming language with comparatively little open-source training data, yet it targets accelerators that are increasingly present in production AI clusters. This asymmetry can be empirically observed: SOTA LLMs generally produce fluent CUDA, but when generating HIP the models might hallucinate APIs or emit kernels that appear plausible but fail at compile time or under multi-seed correctness.
Approach
We investigate three complementary ideas: (1) expanding the task space with synthetic PyTorch workloads, (2) optimizing kernels through multi-agent evolutionary search, and (3) training a small, low-cost open source model (Qwen2.5-Coder-14B-Instruct) with SFT followed by GRPO-based RL. We measure all approaches on kernel compilation, correctness, and runtime performance using KernelBench extended to AMD MI350X GPUs (Ouyang et al., 2025).
Our approach is as follows:
1. Synthetic Data Generation
We generate a corpus of verified HIP kernels paired with PyTorch references using a multi-agent pipeline with Gemini-2.5-Flash. The pipeline has eight cooperating agents:
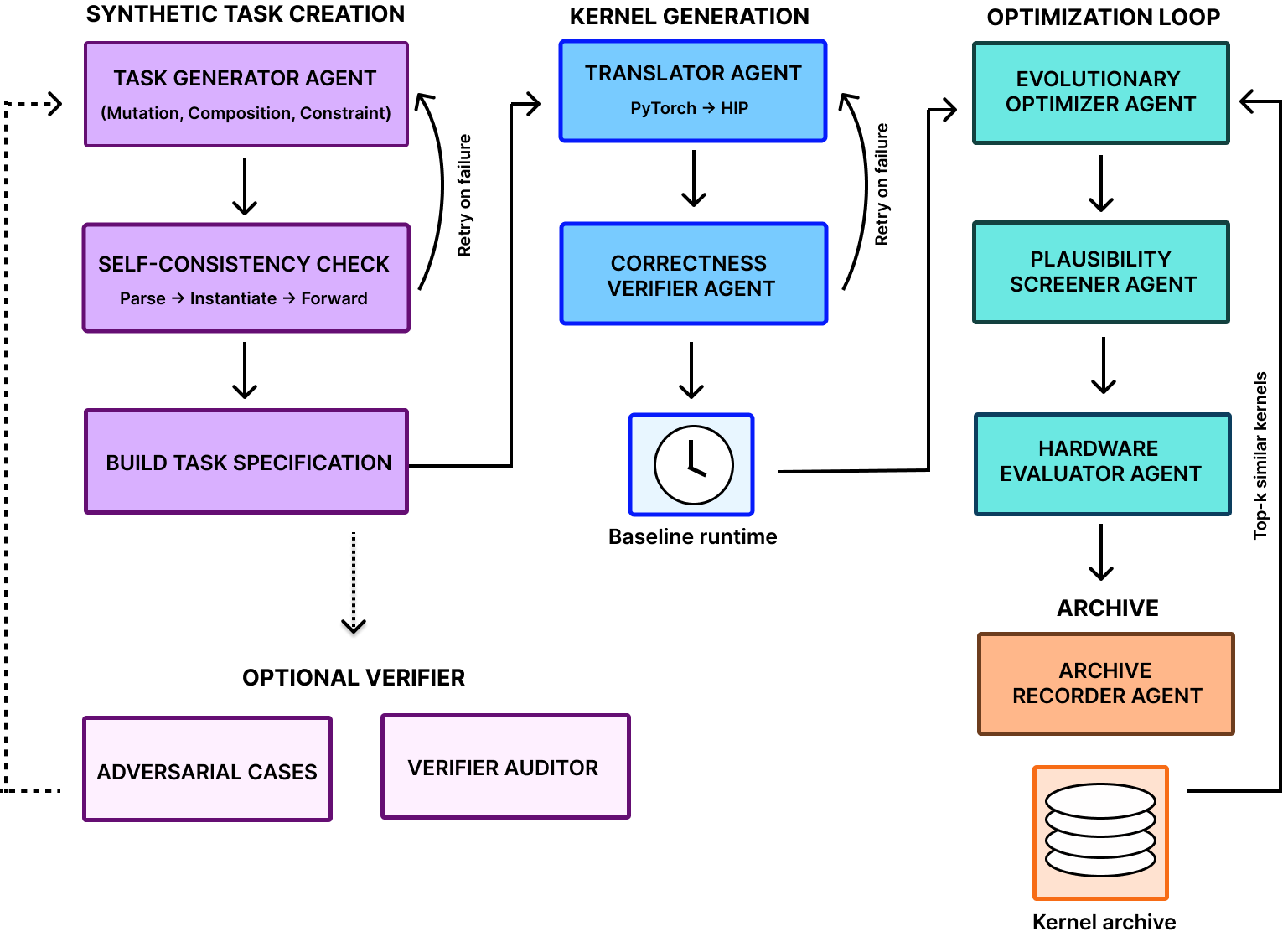
Task Generator: Wraps a PyTorch reference into a structured task and synthesizes new reference modules via mutation*, composition*, and constraint-based generation*, with each synthesized module sanity-checked before entering the pipeline.
Translator: Produces the first working HIP kernel from the PyTorch reference, retrying with the verifier’s error and the previous attempt fed back into the prompt. For each synthetic data task, the agent produced a correct kernel within five attempts.
Correctness Verifier: The deterministic correctness gate that rejects shortcut patterns and runs the candidate against the PyTorch reference across multiple seeds.
Evolutionary Optimizer: Iteratively samples new candidates conditioned on the most similar prior verified kernels following Lange et al., 2025, the current best kernel, and a memory of recent failures, keeping the fastest correct kernel as the seed for the next generation.
Plausibility Screener: An LLM-based reviewer that scores each candidate on compilation and plausibility so only promising kernels reach the GPU.
Hardware Evaluator: Compiles each surviving candidate on AMD MI350X GPUs, checks correctness against the PyTorch reference across multiple seeds, and measures runtime.
Archive Manager: Persists every candidate with its labels, scores, and runtimes to a per-task archive and emits SFT and RL training records for downstream post-training.
Offline Auditors: A paired generator and auditor that run curated correct, broken, and deceptive test cases through both verifiers and report each verifier’s false positives and false negatives against their expected labels.
*Modes of Task Generation
Mutation: We take a subset of existing KernelBench problems and ask the model to generate semantically related variants. These mutations preserve the overall structure of the original workload while modifying computational properties such as operation mix, tensor shapes, batching structure, or fusion patterns. Although closely related to the source task, the resulting kernels can require meaningfully different optimization strategies.
Composition: We generate entirely new workloads by composing operators drawn from a custom 14-operator template library. For each candidate, we randomly sample a subset of operators and instruct the model to combine them into a single shape-compatible PyTorch module. Repeated sampling produces diverse workloads with different operator orderings, tensor shapes, and fusion structures.
Constraint: We specify workloads directly through natural language constraints describing the desired computation, tensor properties, and structural requirements. The model must interpret the specification, construct a valid module architecture, and generate executable code.
2. SFT
We fine-tune Qwen2.5-Coder-14B-Instruct on the synthetic corpus for 3 epochs with a batch size of 2 and a learning rate of 2e-5.
3. RL
We apply reinforcement learning using Group Relative Policy Optimization (GRPO) on the synthetic corpus, where the model generates 4 candidate kernels per prompt and learns from the relative performance between candidates. We adopt Dr. Kernel’s Turn-Reinforce-Leave-One-Out (TRLOO) idea for advantage estimation and reward structure (Liu et al., 2026). TRLOO solves the problem of self-inclusion bias by excluding a candidate in the estimation for its group’s mean reward. The reward signal includes kernel execution on AMD MI350X hardware; a kernel earns positive reward if it compiles and passes correctness checks, with magnitude scaled by measured speedup over PyTorch, capped at 3x.
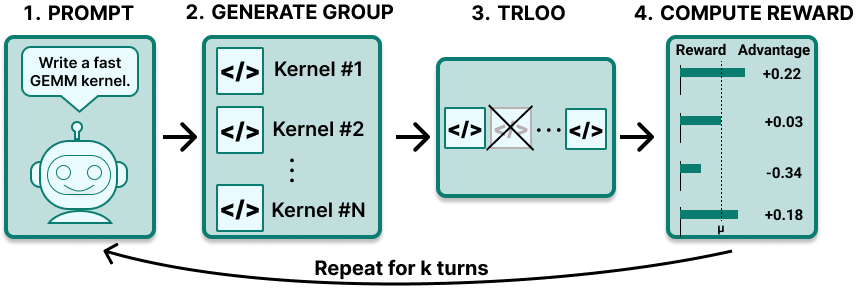
We implemented three key modifications:
- Multi-turn episodes: If a kernel fails, the model receives the error and its failed attempt and is allowed up to 3 additional attempts for each candidate kernel in the group following Baronio et al., 2025.
- Reward smoothing: We track a rolling window of the last 100 rewards and clip any outliers greater than 1.5 standard deviations from the mean. This prevents abnormal GPU timing measurements from distorting the reward signal.
- A summarization agent: Prior to training, we ran a summarizer agent over all agentic pipeline failure logs to extract lessons. These lessons are injected directly into the RL prompts, so the model learns from the reward signals as well as guidance about past mistakes to avoid.
Results and Discussion
Compilation Results
The first metric we evaluate generated kernels on is compilation rate: the percentage of kernels that successfully compile and execute. We compare three different settings: the baseline model, SFT, and GRPO. Across all three KernelBench levels, we see a major improvement from baseline model to SFT and again from SFT to RL.
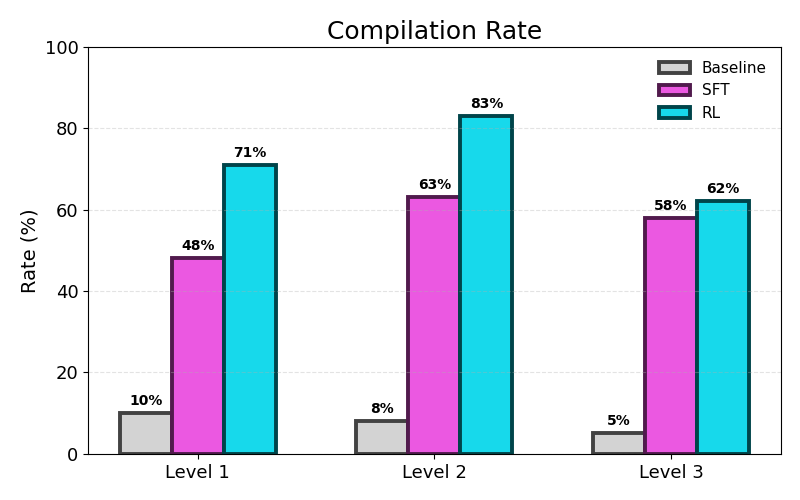
What the Model Learned about HIP Compilation
Interestingly, after qualitative analysis of the generated kernels, we found that the baseline model often produced kernels that looked correct syntactically, but failed to compile because of deeper misunderstandings about HIP kernels, such as accessing invalid memory and incorrect API usage. These failures were especially common on KernelBench Level 1 tasks. Because many Level 1 tasks consisted of only a few operations, the model often attempted to rewrite the entire computation as a custom HIP kernel rather than preserving some existing PyTorch operators.
In some cases, these failures were surprisingly basic. For example, Level 1 Problems 1-15 kernels all contained stray markdown tokens, making the candidates invalid before compilation could even begin.
With SFT, we found that the model started to learn recurring HIP implementation patterns from the synthetic training data, including HIP API usage, valid kernel launch configurations, and correct memory access patterns. More importantly, with SFT, the model appeared to develop better judgement about what should be optimized.
For example, in Level 2 Problem 2, the model preserved the expensive ConvTranspose operator and only fused bias-add, clamp, scale, and divide operations into a custom HIP kernel. Similarly, Level 2 Problem 7 fused ReLU, LeakyReLU, GELU, Sigmoid, and bias-add into a single pass. Both examples follow the same strategy: preserve the core computation and optimize only inexpensive surrounding operations.
Level 2 Problem 2 — ConvTranspose2d_BiasAdd_Clamp_Scaling_Clamp_Divide
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.cpp_extension import load_inline
# Must include this line so PyTorch could use HIP compiler for AMD GPUs
os.environ["CXX"] = "hipcc"
conv_transpose_bias_add_clamp_scaling_clamp_divide_cpp_source = """
#include <hip/hip_runtime.h>
#include <torch/extension.h>
#include <cmath> // For fminf, fmaxf
__global__ void conv_transpose_bias_add_clamp_scaling_clamp_divide_kernel(
const float* conv_out_ptr, const float* bias_ptr, float* out_ptr,
int N, int C, int H, int W, int scaling_factor) {
int total_elements = N * C * H * W;
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < total_elements) {
// Calculate the channel index (c) from the flattened index (idx)
// For a tensor (N, C, H, W) flattened row-major, the channel index 'c' for element 'idx' is:
// idx = n * (C*H*W) + c * (H*W) + h * W + w
// So, c = (idx / (H * W)) % C;
int c_idx = (idx / (H * W)) % C;
float val = conv_out_ptr[idx] + bias_ptr[c_idx];
// First clamp (min=0.0, max=1.0)
val = fmaxf(0.0f, fminf(1.0f, val));
// Scale by scaling_factor
val = val * scaling_factor;
// Second clamp (min=0.0, max=1.0)
val = fmaxf(0.0f, fminf(1.0f, val));
// Divide by scaling_factor
val = val / scaling_factor;
out_ptr[idx] = val;
}
}
torch::Tensor conv_transpose_bias_add_clamp_scaling_clamp_divide_hip(
torch::Tensor conv_out, torch::Tensor bias, float scaling_factor) {
// Ensure tensors are on the same device and are contiguous
// Contiguous memory layout is crucial for correct pointer arithmetic in the kernel
conv_out = conv_out.contiguous();
bias = bias.contiguous();
// Get dimensions of the output from conv_transpose
int N = conv_out.size(0);
int C = conv_out.size(1);
int H = conv_out.size(2);
int W = conv_out.size(3);
// Output tensor will have the same shape as conv_out
auto out = torch::empty_like(conv_out);
const int block_size = 256;
const int total_elements = N * C * H * W;
const int num_blocks = (total_elements + block_size - 1) / block_size;
hipLaunchKernelGGL(conv_transpose_bias_add_clamp_scaling_clamp_divide_kernel,
dim3(num_blocks), dim3(block_size), 0, 0,
conv_out.data_ptr<float>(),
bias.data_ptr<float>(),
out.data_ptr<float>(),
N, C, H, W,
static_cast<int>(scaling_factor));
return out;
}
"""
conv_transpose_bias_add_clamp_scaling_clamp_divide = load_inline(
name="conv_transpose_bias_add_clamp_scaling_clamp_divide",
cpp_sources=conv_transpose_bias_add_clamp_scaling_clamp_divide_cpp_source,
functions=["conv_transpose_bias_add_clamp_scaling_clamp_divide_hip"],
verbose=True,
)
class ModelNew(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, output_padding, bias_shape, scaling_factor):
super(ModelNew, self).__init__()
self.conv_transpose = nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, output_padding=output_padding)
self.bias = nn.Parameter(torch.randn(bias_shape))
self.scaling_factor = scaling_factor
self.fused_op = conv_transpose_bias_add_clamp_scaling_clamp_divide
def forward(self, x):
x = self.conv_transpose(x)
return self.fused_op.conv_transpose_bias_add_clamp_scaling_clamp_divide_hip(x, self.bias, self.scaling_factor)
Level 2 Problem 7 — Conv3d_ReLU_LeakyReLU_GELU_Sigmoid_BiasAdd
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.cpp_extension import load_inline
# Must include this line so PyTorch could use HIP compiler for AMD GPUs
os.environ["CXX"] = "hipcc"
conv3d_relu_leakyrelu_gelu_sigmoid_biasadd_cpp_source = """
#include <hip/hip_runtime.h>
#include <cmath> // For expf, erff, sqrtf
// Fused kernel for ReLU, LeakyReLU, GELU, Sigmoid, and BiasAdd
__global__ void fused_activations_biasadd_kernel(
const float* conv_out_ptr, const float* bias_ptr, float* out_ptr,
int N, int C, int D, int H, int W, float leaky_relu_slope) {
int total_elements = N * C * D * H * W;
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < total_elements) {
float val = conv_out_ptr[idx];
// 1. ReLU: max(0, val)
val = (val > 0) ? val : 0;
// 2. LeakyReLU: val if val > 0 else val * negative_slope
val = (val > 0) ? val : val * leaky_relu_slope;
// 3. GELU (using approximation with erff, matching PyTorch's default 'tanh' approximation if not specified)
// PyTorch's default GELU is 0.5 * x * (1 + erf(x / sqrt(2)))
val = 0.5f * val * (1.0f + erff(val * 0.70710678118f)); // 0.70710678118f is 1/sqrt(2)
// 4. Sigmoid: 1 / (1 + exp(-val))
val = 1.0f / (1.0f + expf(-val));
// 5. BiasAdd: val + bias[c]
int c_idx = (idx / (D * H * W)) % C; // Calculate channel index for bias addition
val = val + bias_ptr[c_idx];
out_ptr[idx] = val;
}
}
torch::Tensor fused_activations_biasadd_hip(
torch::Tensor conv_out, torch::Tensor bias, float leaky_relu_slope) {
// Ensure tensors are on the same device and are contiguous
TORCH_CHECK(conv_out.is_cuda(), "Input tensor must be on CUDA (HIP) device.");
TORCH_CHECK(bias.is_cuda(), "Bias tensor must be on CUDA (HIP) device.");
TORCH_CHECK(conv_out.is_contiguous(), "Input tensor must be contiguous.");
TORCH_CHECK(bias.is_contiguous(), "Bias tensor must be contiguous.");
// Get dimensions from the input tensor
int N = conv_out.size(0);
int C = conv_out.size(1);
int D = conv_out.size(2);
int H = conv_out.size(3);
int W = conv_out.size(4);
// Output tensor will have the same shape as conv_out
auto out = torch::empty_like(conv_out);
const int block_size = 256;
const int total_elements = N * C * D * H * W;
const int num_blocks = (total_elements + block_size - 1) / block_size;
fused_activations_biasadd_kernel<<<num_blocks, block_size>>>(
conv_out.data_ptr<float>(), bias.data_ptr<float>(), out.data_ptr<float>(),
N, C, D, H, W, leaky_relu_slope);
return out;
}
"""
fused_ops = load_inline(
name="fused_activations_biasadd",
cpp_sources=conv3d_relu_leakyrelu_gelu_sigmoid_biasadd_cpp_source,
functions=["fused_activations_biasadd_hip"],
verbose=True,
)
class ModelNew(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, bias_shape):
super(ModelNew, self).__init__()
self.conv = nn.Conv3d(in_channels, out_channels, kernel_size).cuda()
self.bias = nn.Parameter(torch.randn(bias_shape)).cuda()
self.fused_ops = fused_ops
def forward(self, x):
x = self.conv(x)
# Call the fused kernel for all activation functions and bias addition
return self.fused_ops.fused_activations_biasadd_hip(x, self.bias, 0.01)
The weakest SFT generations attempted the opposite approach. In Level 2 Problem 3, the model began an over-ambitious rewrite of the entire block: it defined separate custom kernels for ConvTranspose3D, LayerNorm, AvgPool3D, and GELU, but the generation did not complete the forward method, so the candidate failed before we could evaluate whether the rewritten computation was correct.
Level 2 Problem 3 — ConvTranspose3d_Sum_LayerNorm_AvgPool_GELU
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.cpp_extension import load_inline
# Must include this line so PyTorch could use HIP compiler for AMD GPUs
os.environ["CXX"] = "hipcc"
conv_transpose_sum_cpp_source = """
#include <hip/hip_runtime.h>
#include <torch/extension.h>
#include <cmath> // For erff
__global__ void conv_transpose_sum_kernel(const float* input, const float* sum_weight, float* output,
int N, int C, int D_out, int H_out, int W_out,
int D_in, int H_in, int W_in,
int K_d, int K_h, int K_w,
int S_d, int S_h, int S_w,
int P_d, int P_h, int P_w,
int O_d, int O_h, int O_w) {
int n_idx = blockIdx.x;
int c_idx = blockIdx.y;
if (n_idx < N && c_idx < C) {
int d_out_start = n_idx * C * D_out + c_idx * D_out;
int d_in_start = n_idx * C * D_in + c_idx * D_in;
for (int d_out = 0; d_out < D_out; ++d_out) {
for (int h_out = 0; h_out < H_out; ++h_out) {
for (int w_out = 0; w_out < W_out; ++w_out) {
float sum_val = 0.0f;
int d_out_global = d_out * S_d - P_d + O_d;
int h_out_global = h_out * S_h - P_h + O_h;
int w_out_global = w_out * S_w - P_w + O_w;
for (int k_d = 0; k_d < K_d; ++k_d) {
for (int k_h = 0; k_h < K_h; ++k_h) {
for (int k_w = 0; k_w < K_w; ++k_w) {
int d_in = d_out_global + k_d;
int h_in = h_out_global + k_h;
int w_in = w_out_global + k_w;
if (d_in >= 0 && d_in < D_in && h_in >= 0 && h_in < H_in && w_in >= 0 && w_in < W_in) {
sum_val += input[d_in_start + d_in * H_in * W_in + h_in * W_in + w_in];
}
}
}
}
output[d_out_start + d_out * H_out * W_out + h_out * W_out + w_out] = sum_val + sum_weight[c_idx];
}
}
}
}
}
torch::Tensor conv_transpose_sum_hip(torch::Tensor input, torch::Tensor sum_weight,
int N, int C, int D_out, int H_out, int W_out,
int D_in, int H_in, int W_in,
int K_d, int K_h, int K_w,
int S_d, int S_h, int S_w,
int P_d, int P_h, int P_w,
int O_d, int O_h, int O_w) {
auto output = torch::empty({N, C, D_out, H_out, W_out}, input.options());
const int block_size_x = 16; // Example block size, can be tuned
const int block_size_y = 16; // Example block size, can be tuned
const int num_blocks_x = N;
const int num_blocks_y = C;
dim3 grid(num_blocks_x, num_blocks_y);
dim3 block(block_size_x, block_size_y);
conv_transpose_sum_kernel<<<grid, block>>>(
input.data_ptr<float>(), sum_weight.data_ptr<float>(), output.data_ptr<float>(),
N, C, D_out, H_out, W_out,
D_in, H_in, W_in,
K_d, K_h, K_w,
S_d, S_h, S_w,
P_d, P_h, P_w,
O_d, O_h, O_w
);
return output;
}
"""
layer_norm_cpp_source = """
#include <hip/hip_runtime.h>
#include <torch/extension.h>
#include <cmath> // For sqrtf
__global__ void layer_norm_kernel(const float* input, float* output,
float* gamma, float* beta,
int N, int C, int D, int H, int W,
int norm_dim) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int total_elements = N * C * D * H * W;
if (idx < total_elements) {
int c_idx = idx / (D * H * W);
float mean_val = 0.0f;
float var_val = 0.0f;
int elements_per_channel = D * H * W;
for (int i = 0; i < elements_per_channel; ++i) {
mean_val += input[c_idx * elements_per_channel + i];
}
mean_val /= elements_per_channel;
for (int i = 0; i < elements_per_channel; ++i) {
float diff = input[c_idx * elements_per_channel + i] - mean_val;
var_val += diff * diff;
}
var_val /= elements_per_channel;
float std_dev_val = sqrtf(var_val);
for (int i = 0; i < elements_per_channel; ++i) {
float x = input[c_idx * elements_per_channel + i];
output[c_idx * elements_per_channel + i] = gamma[c_idx] * ((x - mean_val) / std_dev_val) + beta[c_idx];
}
}
}
torch::Tensor layer_norm_hip(torch::Tensor input, torch::Tensor gamma, torch::Tensor beta, int norm_dim) {
auto output = torch::empty_like(input);
const int block_size = 256; // Example block size, can be tuned
const int num_blocks = (input.numel() + block_size - 1) / block_size;
layer_norm_kernel<<<num_blocks, block_size>>>(
input.data_ptr<float>(), output.data_ptr<float>(),
gamma.data_ptr<float>(), beta.data_ptr<float>(),
input.size(0), input.size(1), input.size(2), input.size(3), input.size(4),
norm_dim
);
return output;
}
"""
avg_pool_cpp_source = """
#include <hip/hip_runtime.h>
#include <torch/extension.h>
__global__ void avg_pool_kernel(const float* input, float* output,
int N, int C, int D_out, int H_out, int W_out,
int D_in, int H_in, int W_in,
int K_d, int K_h, int K_w,
int S_d, int S_h, int S_w,
int P_d, int P_h, int P_w) {
int n_idx = blockIdx.x;
int c_idx = blockIdx.y;
if (n_idx < N && c_idx < C) {
int d_out_start = n_idx * C * D_out + c_idx * D_out;
int d_in_start = n_idx * C * D_in + c_idx * D_in;
for (int d_out = 0; d_out < D_out; ++d_out) {
for (int h_out = 0; h_out < H_out; ++h_out) {
for (int w_out = 0; w_out < W_out; ++w_out) {
float sum_val = 0.0f;
int count = 0;
for (int k_d = 0; k_d < K_d; ++k_d) {
for (int k_h = 0; k_h < K_h; ++k_h) {
for (int k_w = 0; k_w < K_w; ++k_w) {
int d_in = d_out * S_d - P_d + k_d;
int h_in = h_out * S_h - P_h + k_h;
int w_in = w_out * S_w - P_w + k_w;
if (d_in >= 0 && d_in < D_in && h_in >= 0 && h_in < H_in && w_in >= 0 && w_in < W_in) {
sum_val += input[d_in_start + d_in * H_in * W_in + h_in * W_in + w_in];
count++;
}
}
}
}
output[d_out_start + d_out * H_out * W_out + h_out * W_out + w_out] = sum_val / count;
}
}
}
}
}
torch::Tensor avg_pool_hip(torch::Tensor input,
int N, int C, int D_out, int H_out, int W_out,
int D_in, int H_in, int W_in,
int K_d, int K_h, int K_w,
int S_d, int S_h, int S_w,
int P_d, int P_h, int P_w) {
auto output = torch::empty({N, C, D_out, H_out, W_out}, input.options());
const int block_size_x = 16; // Example block size, can be tuned
const int block_size_y = 16; // Example block size, can be tuned
const int num_blocks_x = N;
const int num_blocks_y = C;
dim3 grid(num_blocks_x, num_blocks_y);
dim3 block(block_size_x, block_size_y);
avg_pool_kernel<<<grid, block>>>(
input.data_ptr<float>(), output.data_ptr<float>(),
N, C, D_out, H_out, W_out,
D_in, H_in, W_in,
K_d, K_h, K_w,
S_d, S_h, S_w,
P_d, P_h, P_w
);
return output;
}
"""
gelu_cpp_source = """
#include <hip/hip_runtime.h>
#include <torch/extension.h>
#include <cmath> // For erff
__global__ void gelu_kernel(const float* input, float* output, int size) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
output[idx] = input[idx] * 0.5f * (1.0f + erff(input[idx] * M_SQRT1_2F));
}
}
torch::Tensor gelu_hip(torch::Tensor input) {
auto size = input.numel();
auto output = torch::empty_like(input);
const int block_size = 256; // Example block size, can be tuned
const int num_blocks = (size + block_size - 1) / block_size;
gelu_kernel<<<num_blocks, block_size>>>(input.data_ptr<float>(), output.data_ptr<float>(), size);
return output;
}
"""
conv_transpose_sum = load_inline(
name="conv_transpose_sum",
cpp_sources=conv_transpose_sum_cpp_source,
functions=["conv_transpose_sum_hip"],
verbose=True,
)
layer_norm = load_inline(
name="layer_norm",
cpp_sources=layer_norm_cpp_source,
functions=["layer_norm_hip"],
verbose=True,
)
avg_pool = load_inline(
name="avg_pool",
cpp_sources=avg_pool_cpp_source,
functions=["avg_pool_hip"],
verbose=True,
)
gelu = load_inline(
name="gelu",
cpp_sources=gelu_cpp_source,
functions=["gelu_hip"],
verbose=True,
)
class ModelNew(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, output_padding, sum_weight, norm_shape, pool_kernel_size):
super(ModelNew, self).__init__()
# Store parameters for custom kernels
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.output_padding = output_padding
self.norm_shape = norm_shape
self.pool_kernel_size = pool_kernel_size
# Initialize weights and biases for conv_transpose and LayerNorm
self.conv_transpose_weight = nn.Parameter(torch.randn(out_channels, in_channels, *kernel_size))
self.conv_transpose_bias = nn.Parameter(torch.zeros(out_channels))
self.sum_weight = nn.Parameter(torch.tensor(sum_weight))
self.gamma = nn.Parameter(torch.ones(norm_shape))
self.beta = nn.Parameter(torch.zeros(norm_shape))
# Calculate output shapes for custom kernels
self.calculate_output_shapes()
# Load custom kernels
self.conv_transpose_sum_op = conv_transpose_sum
self.layer_norm_op = layer_norm
self.avg_pool_op = avg_pool
self.gelu_op = gelu
def calculate_output_shapes(self):
# Calculate output shape for ConvTranspose3d
N, C_in, D_in, H_in, W_in = 1, self.in_channels, 1, 1, 1 # Use dummy input shape (1, C_in, 1, 1, 1)
dummy_input = torch.empty(N, C_in, D_in, H_in, W_in)
dummy_output = nn.functional.conv_transpose3d(dummy_input, self.conv_transpose_weight, bias=self.conv_transpose_bias,
stride=self.stride, padding=self.padding, output_padding=self.output_padding)
self.D_out, self.H_out, self.W_out = dummy_output.shape[2:]
# Calculate output shape for AvgPool3d
N, C_in, D_in, H_in, W_in = 1, self.out_channels, self.D_out, self.H_out, self.W_out # Use calculated output from conv_transpose
dummy_input = torch.empty(N, C_in, D_in, H_in, W_in)
dummy_output = nn.functional.avg_pool3d(dummy_input, kernel_size=self.pool_kernel_size)
self.D_avg_out, self.H_avg_out, self.W_avg_out = dummy_output.shape[2:]
def forward(self, x):
RL reinforced the successful patterns that emerged during SFT by rewarding the kernels that survived real compiler checks and hardware execution. Rather than discovering entirely new optimization techniques, the model learned which modifications were safe to make. Successful RL generations increasingly favored fusing local operations such as activations and bias additions while preserving the overall structure of the original computation. The result was a consistent shift toward simpler, more reliable optimizations and substantially higher compilation rates across all three KernelBench levels.
Correctness Results
The second metric we looked at is correctness: the percent of kernels that both compile and match the original PyTorch reference outputs. Here, we expect to see a jump in correctness between fine tuning and reinforcement learning because correctness is directly part of our reward signal. Interestingly, we see a jump from 13% under SFT to 60% under RL in correctness on Level 2 KernelBench problems.
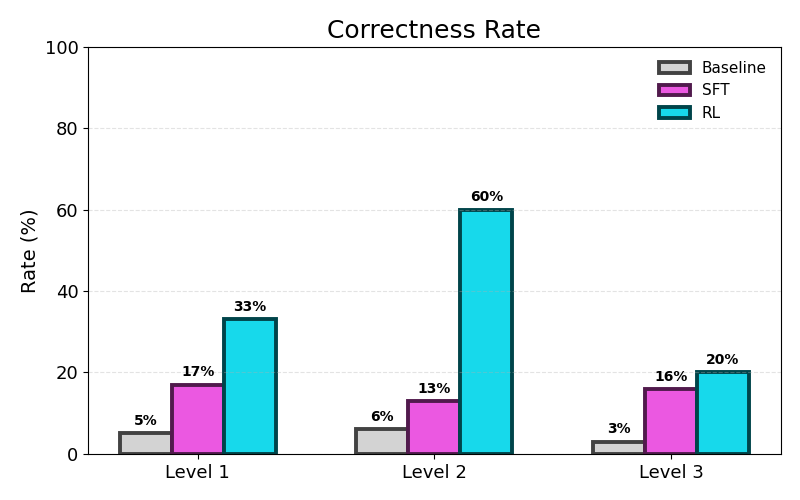
Why RL Helped Level 2 So Much
The largest correctness gains occurred on Level 2 because these tasks are built around simple fusion opportunities. Unlike Level 1, which focuses on implementing individual operators, and Level 3, which requires preserving the behavior of entire model architectures, every Level 2 problem contains a direct opportunity to fuse a short sequence of operations.
After fine-tuning, although the model learned local fusion patterns, it often applied them incorrectly. A recurring failure mode was modifying more of the computation than necessary. For example, in Level 2 Problem 4, the generated kernel correctly identified the fusion opportunity, but implemented an additional convolution inside the custom HIP kernel.
Level 2 Problem 4 — Conv2d_Mish_Mish
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.cpp_extension import load_inline
# Must include this line so PyTorch could use HIP compiler for AMD GPUs
os.environ["CXX"] = "hipcc"
conv_mish_mish_cpp_source = """
#include <hip/hip_runtime.h>
#include <cmath> // For tanhf, expf, logf
// Define the Mish activation function: x * tanh(softplus(x)) where softplus(x) = log(1 + exp(x))
__device__ float mish_activation(float x) {
return x * tanhf(logf(1.0f + expf(x)));
}
__global__ void conv_mish_mish_kernel(
const float* input,
const float* weight,
float* output,
int N, int C_in, int H_in, int W_in,
int C_out, int K, int stride, int padding) {
int n_idx = blockIdx.x;
int total_batches = N * C_out;
if (n_idx < total_batches) {
int n = n_idx / C_out;
int c_out = n_idx % C_out;
// Output spatial dimensions
int H_out = (H_in + 2 * padding - K) / stride + 1;
int W_out = (W_in + 2 * padding - K) / stride + 1;
// Loop through output spatial locations
for (int h_out = 0; h_out < H_out; ++h_out) {
for (int w_out = 0; w_out < W_out; ++w_out) {
float sum = 0.0f;
// Input spatial dimensions for convolution
int h_start = h_out * stride - padding;
int w_start = w_out * stride - padding;
// Perform convolution (correlation)
for (int c_in = 0; c_in < C_in; ++c_in) {
for (int k_h = 0; k_h < K; ++k_h) {
for (int k_w = 0; k_w < K; ++k_w) {
int h_in = h_start + k_h;
int w_in = w_start + k_w;
// Check bounds for input (implicit padding handling)
if (h_in >= 0 && h_in < H_in && w_in >= 0 && w_in < W_in) {
int input_idx = n * C_in * H_in * W_in +
c_in * H_in * W_in +
h_in * W_in + w_in;
int weight_idx = c_out * C_in * K * K +
c_in * K * K +
k_h * K + k_w;
sum += input[input_idx] * weight[weight_idx];
}
}
}
}
// Apply first Mish activation
float val_after_first_mish = mish_activation(sum);
// Apply second Mish activation
float val_after_second_mish = mish_activation(val_after_first_mish);
// Store result
int output_idx = n * C_out * H_out * W_out +
c_out * H_out * W_out +
h_out * W_out + w_out;
output[output_idx] = val_after_second_mish;
}
}
}
}
torch::Tensor conv_mish_mish_hip(
torch::Tensor input,
torch::Tensor weight,
int stride,
int padding) {
// Ensure tensors are on the same device and are contiguous
input = input.contiguous();
weight = weight.contiguous();
// Get dimensions from input tensors
int N = input.size(0);
int C_in = input.size(1);
int H_in = input.size(2);
int W_in = input.size(3);
int C_out = weight.size(0);
int K = weight.size(2); // Assuming square kernel
// Calculate output spatial dimensions
int H_out = (H_in + 2 * padding - K) / stride + 1;
int W_out = (W_in + 2 * padding - K) / stride + 1;
// Create output tensor
auto output = torch::empty({N, C_out, H_out, W_out}, input.options());
const int block_size = 256;
const int total_batches = N * C_out;
const int num_blocks = (total_batches + block_size - 1) / block_size;
conv_mish_mish_kernel<<<num_blocks, block_size>>>(
input.data_ptr<float>(),
weight.data_ptr<float>(),
output.data_ptr<float>(),
N, C_in, H_in, W_in,
C_out, K, stride, padding);
return output;
}
"""
conv_mish_mish = load_inline(
name="conv_mish_mish",
cpp_sources=conv_mish_mish_cpp_source,
functions=["conv_mish_mish_hip"],
verbose=True,
)
class ModelNew(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size):
super(ModelNew, self).__init__()
# Initialize the convolution layer and move it to the GPU
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size).cuda()
self.conv_mish_mish = conv_mish_mish
def forward(self, x):
# Ensure the input tensor is on the GPU before processing
if not x.is_cuda:
x = x.cuda()
# Extract parameters needed for the custom kernel
weight = self.conv.weight
bias = self.conv.bias
stride = self.conv.stride[0] # Assuming square stride
padding = self.conv.padding[0] # Assuming square padding
dilation = self.conv.dilation[0] # Assuming square dilation
groups = self.conv.groups
# If there's a bias, we need to add it after the convolution
# For simplicity, and because the original problem focuses on fusion,
# we'll handle the bias addition in PyTorch and then pass to the kernel.
# A more advanced optimization would fuse bias addition into the kernel.
if bias is not None:
x = self.conv.convolution(input=x, weight=weight, bias=None, stride=stride, padding=padding, dilation=dilation, groups=groups)
x = x + bias.view(1, -1, 1, 1)
else:
x = self.conv.convolution(input=x, weight=weight, bias=None, stride=stride, padding=padding, dilation=dilation, groups=groups)
# Call the fused HIP kernel for convolution followed by two Mish activations
return self.conv_mish_mish.conv_mish_mish_hip(x, weight, stride, padding)
RL directly penalized these mistakes because the reward depends on correctness. Since the same fusion pattern appears regularly throughout the Level 2 tasks, successful behaviors transferred naturally across many tasks.
Why Level 3 Remains Difficult
Although RL substantially improved correctness on Level 2 tasks, Level 3 remained challenging. Unlike earlier levels, many Level 3 workloads require preserving the behavior of entire workloads rather than individual operators.
Level 3 Problem 28 is a good example of this. The task implements a Vision Transformer, which divides an image into patches, projects each patch into a learned embedding space, adds position information, and processes the resulting sequence with a Transformer before classification. Although the generated kernel correctly identifies the patch-extraction stage, it never performs a learned patch to embedding transformation. So, instead of sending learned patch embeddings to the Transformer, it sends raw patch values. This failure differs fundamentally from the syntax and API errors common in the baseline model.
Level 3 Problem 28 — VisionTransformer
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.cpp_extension import load_inline
# Must include this line so PyTorch could use HIP compiler for AMD GPUs
os.environ["CXX"] = "hipcc"
# Custom HIP kernel for patch extraction and linear transformation
patch_extract_linear_cpp_source = """
#include <hip/hip_runtime.h>
#include <torch/extension.h>
__global__ void patch_extract_linear_kernel(const float* img, float* out, int B, int C, int H, int W, int p, int dim) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int total_patches = B * (H / p) * (W / p);
if (idx < total_patches) {
int b_idx = idx / ((H / p) * (W / p));
int patch_idx = idx % ((H / p) * (W / p));
int h_idx = patch_idx / (W / p);
int w_idx = patch_idx % (W / p);
int patch_offset = b_idx * C * H * W + h_idx * p * W * C + w_idx * p * C;
// Extract patch and perform linear transformation
// Each thread processes one element of the patch.
for (int c = 0; c < C; ++c) {
for (int ph = 0; ph < p; ++ph) {
for (int pw = 0; pw < p; ++pw) {
int linear_idx = idx * dim + c * p * p + ph * p + pw;
int img_linear_idx = patch_offset + c * H * W + ph * W + pw;
out[linear_idx] = img[img_linear_idx];
}
}
}
}
}
torch::Tensor patch_extract_linear_hip(torch::Tensor img, int p, int dim) {
// Input validation
TORCH_CHECK(img.is_cuda(), "Input tensor must be on GPU");
TORCH_CHECK(img.is_floating_point(), "Input tensor must be a floating-point type");
TORCH_CHECK(img.dtype() == torch::kFloat32, "Input tensor must be float32");
TORCH_CHECK(img.dim() == 4, "Input tensor must be 4-dimensional (B, C, H, W)");
int B = img.size(0);
int C = img.size(1);
int H = img.size(2);
int W = img.size(3);
// Calculate the total number of patches
int total_patches = B * (H / p) * (W / p);
// Output tensor shape: (total_patches, dim)
auto out = torch::zeros({total_patches, dim}, img.options());
const int block_size = 256;
const int num_blocks = (total_patches + block_size - 1) / block_size;
patch_extract_linear_kernel<<<num_blocks, block_size>>>(
img.data_ptr<float>(),
out.data_ptr<float>(),
B, C, H, W, p, dim
);
return out;
}
"""
# Custom HIP kernel for adding positional embeddings
add_pos_embedding_cpp_source = """
#include <hip/hip_runtime.h>
#include <torch/extension.h>
__global__ void add_pos_embedding_kernel(const float* x, const float* pos_embedding, float* out, int B, int N, int D) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int total_elements = B * N * D;
if (idx < total_elements) {
int b_idx = idx / (N * D);
int n_idx = (idx / D) % N;
int d_idx = idx % D;
// Positional embedding is (1, N+1, D), so we need to offset by 1 for patches (0 is for cls_token)
out[idx] = x[idx] + pos_embedding[1 * (N + 1) * D + n_idx * D + d_idx];
}
}
torch::Tensor add_pos_embedding_hip(torch::Tensor x, torch::Tensor pos_embedding) {
// Input validation
TORCH_CHECK(x.is_cuda(), "Input tensor 'x' must be on GPU");
TORCH_CHECK(pos_embedding.is_cuda(), "Input tensor 'pos_embedding' must be on GPU");
TORCH_CHECK(x.is_floating_point(), "Input tensor 'x' must be a floating-point type");
TORCH_CHECK(pos_embedding.is_floating_point(), "Input tensor 'pos_embedding' must be a floating-point type");
TORCH_CHECK(x.dtype() == torch::kFloat32, "Input tensor 'x' must be float32");
TORCH_CHECK(pos_embedding.dtype() == torch::kFloat32, "Input tensor 'pos_embedding' must be float32");
TORCH_CHECK(x.dim() == 3, "Input tensor 'x' must be 3-dimensional (B, N, D)");
TORCH_CHECK(pos_embedding.dim() == 3, "Input tensor 'pos_embedding' must be 3-dimensional (1, N+1, D)");
int B = x.size(0);
int N = x.size(1);
int D = x.size(2);
// Output tensor shape: (B, N, D)
auto out = torch::zeros_like(x);
const int block_size = 256;
const int num_blocks = (B * N * D + block_size - 1) / block_size;
add_pos_embedding_kernel<<<num_blocks, block_size>>>(
x.data_ptr<float>(),
pos_embedding.data_ptr<float>(),
out.data_ptr<float>(),
B, N, D
);
return out;
}
"""
# Load the custom HIP kernels
patch_extract_linear = load_inline(
name="patch_extract_linear",
cpp_sources=patch_extract_linear_cpp_source,
functions=["patch_extract_linear_hip"],
verbose=True,
)
add_pos_embedding = load_inline(
name="add_pos_embedding",
cpp_sources=add_pos_embedding_cpp_source,
functions=["add_pos_embedding_hip"],
verbose=True,
)
class ModelNew(nn.Module):
def __init__(self, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, channels=3, dropout=0.1, emb_dropout=0.1):
"""
Vision Transformer (ViT) model.
:param image_size: The size of the input image (assumed to be square).
:param patch_size: The size of each patch (assumed to be square).
:param num_classes: The number of output classes.
:param dim: The dimensionality of the embedding space.
:param depth: The number of transformer layers.
:param heads: The number of attention heads.
:param mlp_dim: The dimensionality of the MLP (Multi-Layer Perceptron) in the transformer.
:param channels: The number of channels in the input image (default is 3 for RGB).
:param dropout: Dropout rate applied in the MLP.
:param emb_dropout: Dropout rate applied to the embedded patches.
"""
super(ModelNew, self).__init__()
assert image_size % patch_size == 0, "Image dimensions must be divisible by the patch size."
num_patches = (image_size // patch_size) ** 2
patch_dim = channels * patch_size ** 2
self.patch_size = patch_size
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.patch_to_embedding = nn.Linear(patch_dim, dim)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=dim, nhead=heads, dim_feedforward=mlp_dim, dropout=dropout),
num_layers=depth
)
self.to_cls_token = nn.Identity()
self.mlp_head = nn.Sequential(
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, num_classes)
)
def forward(self, img):
"""
Forward pass of the Vision Transformer.
:param img: The input image tensor, shape (batch_size, channels, image_size, image_size).
:return: The output tensor, shape (batch_size, num_classes).
"""
p = self.patch_size
# Use custom HIP kernel for patch extraction and linear transformation
x = patch_extract_linear.patch_extract_linear_hip(img, p, self.patch_to_embedding.out_features)
# Add class token
cls_tokens = self.cls_token.expand(img.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# Use custom HIP kernel for adding positional embeddings
x = add_pos_embedding.add_pos_embedding_hip(x, self.pos_embedding)
x = self.dropout(x)
# PyTorch's nn.TransformerEncoder expects input shape (N, S, E)
# where N is the batch size, S is the sequence length, and E is the embedding dimension.
# Our x is already in this format (B, N+1, D).
x = self.transformer(x)
# Extract the cls_token representation
x = self.to_cls_token(x[:, 0])
return self.mlp_head(x)
Further, one recurring correctness failure, particularly in Level 3, was parameter reinitialization. Across multiple problems, the generated kernels instantiated new parameters using patterns such as:
self.weight = nn.Parameter(torch.randn(…)).
This issue appeared in Level 3 Problems 5, 13, 28, 32, 35, 38, 41, 46, and 49, among others. Although these implementations often looked structurally correct, they could never match the reference outputs because they were computing with entirely different weights.
What Optimization Patterns Did The Model Learn?
Across all levels and experiments, we observed several recurring GPU optimization patterns.
-
Operator fusion. The most common optimization was fusing chains of elementwise operations such as activations, bias additions, scaling, and normalization into a single HIP kernel. This reduces kernel launch overhead and avoids unnecessary intermediate tensors.
-
Shared-memory reductions. Several generated softmax and normalization kernels allocated shared memory, accumulated partial results across threads, and used synchronization primitives to perform reductions.
-
Tiled matrix multiplication. Some generated GEMM kernels divided the output into tiles, loaded data into shared memory, and accumulated partial products before writing the final result.
-
Selective optimization. Rather than replacing expensive convolutions or matrix multiplications, many successful kernels focused on simpler surrounding operations while preserving the core computation. This behavior appeared repeatedly in both SFT and RL generations.
Performance Results
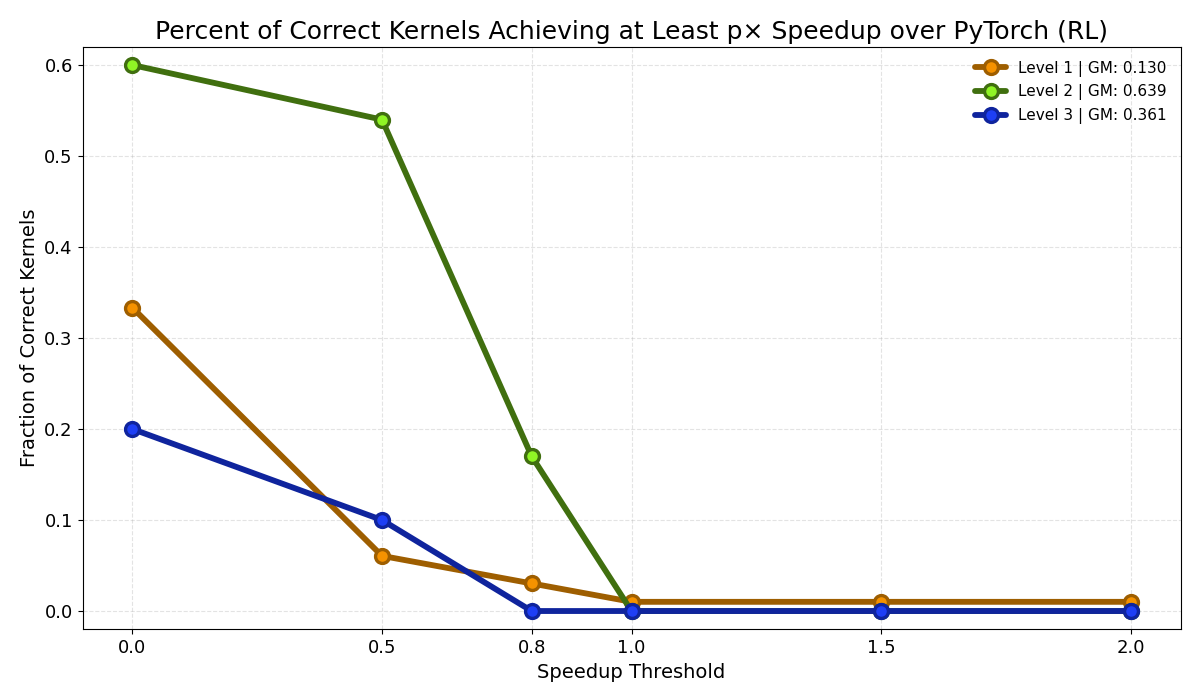
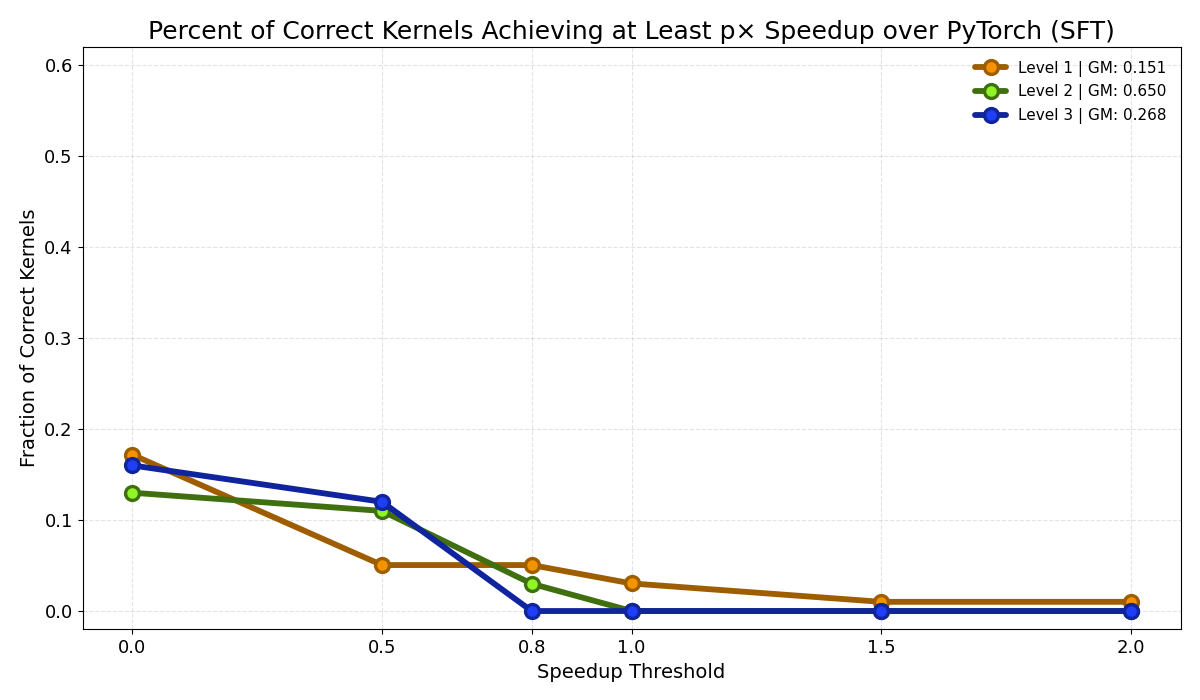
While RL improved compilation and correctness, meaningful performance gains remained difficult to achieve. The figure reports fastp, the fraction of correct kernels achieving at least a p-times speedup over the PyTorch baseline (Ouyang et al., 2025).
The strongest results occurred on Level 2, where roughly 60% of correct kernels matched PyTorch performance and over half achieved at least a 0.5× speedup over PyTorch baselines. However, the fraction of kernels achieving larger speedups dropped rapidly across all levels. No kernels achieved large performance improvements.
This behavior is consistent with what we observed in the generated kernels. Both SFT and RL learned local optimization strategies. Rather than replacing expensive operators, the generated kernels typically fused only the surrounding elementwise computation. This improved correctness and reduced overhead, but left the dominant computational cost of the workload in PyTorch, limiting any meaningful performance gain.
Comparison to Prior Work
Comparing HIP kernel generation systems remains challenging because there is no widely adopted benchmark or evaluation protocol. Existing studies differ substantially in benchmark size, task construction, hardware platforms, and evaluation methodology, making direct numerical comparisons difficult.
To our knowledge, only a limited number of works report compilation, correctness, and performance metrics for HIP kernel generation on KernelBench tasks. Recent work by AMD evaluates PyTorch-to-HIP translation on a curated benchmark of only 24 tasks sourced from the GPU Mode community and reports strong compilation, correctness, and runtime performance (Younesian et al., 2026). Separately, KernelArena reports results on a 41-problem KernelBench-HIP subset and achieves a median speedup of 1.37x with Opus 4.5. Importantly, both of these works focus on SOTA models and different AMD GPUs.
While these results provide useful points of reference, they are not directly comparable to ours. The benchmarks differ in both size and task distribution, use different versions of KernelBench or entirely custom task collections, and importantly, use expensive frontier models.
Conclusion
We find that synthetic kernel generation, multi-agent evolutionary search, and SFT followed by GRPO-based RL deliver meaningful gains in HIP kernel compilation and correctness on a small open-source model, with RL contributing the largest jump. Speedup over PyTorch remains the harder objective, since correctness alone does not force the model to necessarily reason about the hardware. Pulling ROCm profiler signals into the reward, allowing the model to learn where its kernels are slow or inefficient, is a natural next step for exploration.
Future Works
Another important direction is understanding how performance scales with larger synthetic datasets such as identifying whether compilation and correctness continue to improve with additional synthetic data. We are also interested in failure-driven post-training. One promising direction is to use stronger models with test-time scaling to repeatedly attempt failed problems and add successful solutions back into the training datasets.
Acknowledgements
We would like to sincerely thank AMD, and specifically Aman Salykov and Dr. Sharon Zhou, for their support with this research and for providing the compute that made our research possible. We would also like to thank Simon Guo and Dr. Azalia Mirhoseini from Stanford’s Scaling Intelligence Lab for their mentorship throughout our research.
If you find our work useful, please use the following citation:
@misc{konidala2026hipkernels,
author={Laasya Konidala and Natalia Pahlavan and Annmaria Antony and Simon Guo
and Azalia Mirhoseini},
title={Toward Better HIP Kernel Generation for AMD GPUs: Synthetic Data, Multi-Agent Search,
and Reinforcement Learning},
year={2026},
howpublished={\url{https://scalingintelligence.stanford.edu/blogs/hipkernels/}}
}